인덱스 기본
2021. 12. 8. 22:05
[TOC]
인덱스 기본
- 인덱스 탐색 과정이 수직적 탐색과 수평적 탐색, 두 단계로 이루어진다는 사실을 기억하자
2.1 인덱스 구조 및 탐색
- 어떤 초등학교에서 '홍길동'이라는 학생을 찾는 방법은?
-
- 1학년 1반부터 6학년 마지막 반까지 돌아다니며 홍길동 학생을 찾는다.
- 교무실에서 학생 명부를 조회해 홍길동 학생이 있는 교실만 찾아간다.
-
- 홍길동 학생이 많다면 전자가, 적다면 후자가 빠르다.
- 만약 이름으로 학생을 찾는 경우가 많다면 학생명부를 이름순으로 정렬해두면 편할 것이다.
- 여기서 이름이 인덱스이다.
- 학년-반-번호는 각 학생마다 갖는 고유한 속성이고 이것은 인덱스 ROWID이다.
- DB또한 두가지 방법으로 테이블에서 데이터를 찾는다.
- 테이블 전체 스캔
- 인덱스 이용
- 인덱스의 핵심 요소
- 인덱스는 큰 테이블에서 소량 데이터를 검색할 때 사용함
- 온라인 트랜잭션 처리는 주로 소량 데이터 검색임
- 그러니 인덱스 튜닝이 중요함
- 핵심 요소 두가지는 다음과 같다
- 인덱스 스캔 과정에서 발생하는 비효율 줄이기
- 테이블 엑세스 횟수 줄이기
- 인덱스 스캔 과정에서 발생하는 비효율 줄이기?
- '김'씨인 학생중 키가 '170' 이상인 학생을 찾고 싶다고 해보자
- 만약 이름-키 순으로 정렬이 되어있다면 소량만 스캔해서 결과를 찾을 수 있다.
- 그러나 키-이름 순으로 정렬되어 있다면 더 많은 양을 스캔해야만 찾을 수 있다.
- 테이블 엑세스 횟수를 줄인다?
- 인덱스 스캔 후 테이블 레코드를 엑세스할 때(= 읽을 때) 랜덤 I/O 방식을 사용하므로 이를 '랜덤 엑세스 최소화 튜닝'이라 한다.
- '김'씨 학생은 10명이고 키가 170 이상인 학생은 50명이다.
- 그 중에 170이 넘는 김씨는 3명 뿐이라 해보자.
- 만약 '이름'만으로 정렬한 학생명부 vs '키'만으로 정렬할 학생명부만 있다고 생각해보자
- '이름'으로 정렬된 학생명부에서 인덱스는 이름이고, 명부를 보고 반(테이블)을 방문해야만 키를 확인 할 수 있게된다. 반대의 경우도 마찬가지다.
- 그렇다면 '이름'으로 정렬한 학생명부가 있다면 테이블을 10번만 방문하면 된다. (모든 김씨 체크)
- 그러나 키로 정렬한 학생명부로 방문한다면 50번을 방문해야 한다.
- 인덱스 스캔 효율화 튜닝과 랜덤 액세스 최소화 튜닝 중 랜덤 엑세스 최소화 튜닝이 좀더 중요하다고 할 수 있다.
- 테이블을 직접 찾아가는 비율을 줄여야하기 때문이다.
- SQL 튜닝은 랜덤 I/O 와의 전쟁이다.
인덱스 구조
- 데이터베이스에서 인덱스 없이 데이터를 찾으려면 테이블 전체를 스캔해야한다.
- 반면, 인덱스를 이용하면 일부만 스캔하고 멈출 수 있다.
- 범위 스캔이 가능하다는 의미이다.
- 범위 스캔이 가능한 이유는 인덱스가 정렬 되어있기 때문이다.
- DBMS는 일반적으로 B*Tree 인덱스를 사용한다
- B*Tree 인덱스를 사용하는 이유
- https://helloinyong.tistory.com/296
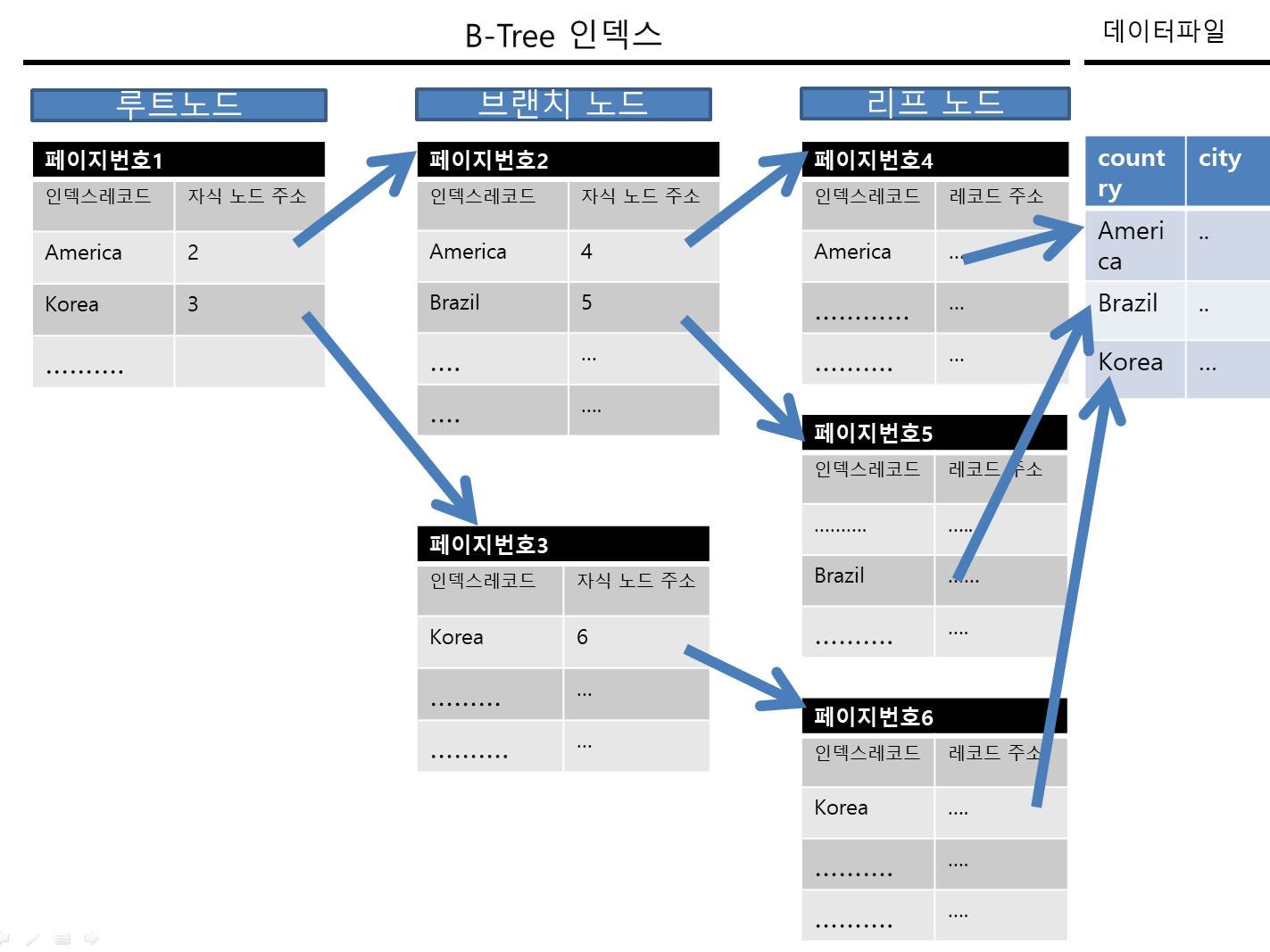
- 리프 블록에 저장된 각 레코드는 키값 순으로 정렬되어 있고 ROWID를 가짐
- 키가 같다면 ROWID 순으로 정렬됨
- 인덱스를 스캔하는 이유는 소량의 데이터를 빨리 찾고 거기서 ROWID를 찾기 위함이다.
- 데이터 구조
- ROWID = 데이터 블록 주소 + 로우 번호
- 데이터 블록 주소 = 데이터 파일 번호 + 블록 번호
- 블로 번호 : 데이터파일 내에서 부여한 상대적 순번
- 로우 번호 : 블록 내 순번
- 인덱스 탐색의 두가지 방법
- 수직적 탐색 : 인덱스 스캔 시작지점을 찾는 과정
- 수평적 탐색 : 데이터를 찾는 과정
*수직적 탐색 *
- 인덱스 스캔의 시작지점을 찾는 작업
*수평적 탐색 *
- 수직적 탐색을 통해 스캔 시작점을 찾으면 찾고자 하는 데이터가 더 나타나지 않을 때 까지 인덱스 리프 블록을 수평적으로 스캔함
- 본격적으로 데이터를 찾는 과정임
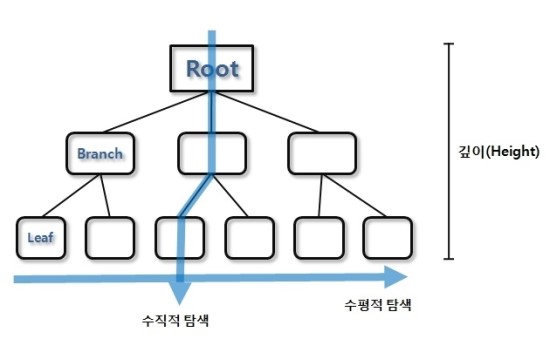
- 수평적 탐색이 끝나면 만족하는 모든 데이터를 찾으면서 ROWID를 얻어온다.
- 인덱스로 끝나는 경우도 있지만 일반적으로 ROWID로 테이블 엑세스함
결합 인덱스 구조와 탐색
- 두가지 이상 조건을 가지고 탐색하는 경우이다.
- 앞서 말했던 이름-키, 혹은 키-이름 순으로 인덱스를 만들었을 때의 차이가 여기서 나타난다.
- 그러나 단순한 엑셀 평면구조와는 다르게 다단계구조이다.
- 엑셀은 이름과 키를 필터링하면 바로 구분해서 보여준다.
- 그러나 DBMS는 '이름'과 '키'를 동시에 가지고 찾아다닌다.
- 엑셀은 하나씩 정렬하여 확인할 수 있지만 DBMS는 두가지 요소를 같이 들고 찾아다닌다.
2.2 인덱스 기본 사용법
- 인덱스를 사용한다는 것은 리프블록에서 스캔 시작점을 찾아 거기서부터 스캔하다가 중간에 멈추는 것을 의미함
- Index Range Scan을 의미
- 검색의 시작점을 찾는 것
- 스캔 시작점을 찾기 못하면 전체를 스캔하는 Index Full Scan 방식으로 작동하게 됨
Index를 Range Scan 할 수 없는 상황
- Index는 검색의 '시작점'을 찾는 작업
- 인덱스 컬럼을 가공하게 되면 시작점을 찾을 수가 없음
- 정렬이 깨진다는 의미임
- '생년월일'으로 줄세워진 데이터에서 다음의 데이터를 검색할 것이다
- 2000년 1월생을 찾는다고하면 2000년 1월부터 2000년 2월이 나오기 전까지 검색을 진행하면 된다.
- 그러나 그냥 1월생을 찾는다고 한다면 시작점과 끝점이 명확하지 않을 것이다.
인덱스 사용 조건
- 인덱스를 Range Scan 하기 위한 가장 첫 번째 조건은 인덱스 선두 컬럼이 조건절에 있어야 한다.
- [소속팀 + 사원명 + 연령]으로 정렬된 데이터에서 '사원명'으로 검색한다면, 소속팀마다 여러 이름들이 흩어져 있을 것이다.
- 반대로 인덱스 선두 컬럼이 가공되지 않은 상태로 조건절에 있으면 인덱스 Range Scan은 무조건 가능하다.
- 그러나 Range Scan이 항상 좋은 성능을 보장하는 것은 아니다.
인덱스를 이용한 소트 연산 생략
- 소트 연산이란?
- 데이터 정렬 작업
- [장비 번호 + 변경일자 + 변경순번]순으로 구성한 상태변경이력 테이블이 있다고 할때
- 장비번호와 변경일자가 동일한 데이터들은 변경순번으로 정렬된다.
- 여기서 특정 장비번호와 변경일자를 가진 데이터를 찾으면 알아서 정렬된 변경순번을 얻을 수 있다.
2.3 인덱스 확장기능 사용법
Index Range Scan
- B* tree 인덱스의 가장 일반적이고 정상적인 형태의 엑세스 방식
- 실행 계획
select * from emp where deptno = 20;
Execution Plan
------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS
1 0 TABLE ACCESS (BY INDEX ROWID) OF 'EMP' (TABLE)
2 1 INDEX (RANGE SCAN) OF 'EMP_DEPTNO_IDX' (INDEX)- 주의 사항
- 선두 컬럼을 가공하면 Range Scan 불가
- 인덱스를 잘 탄다고 해서 성능이 좋다는 의미로 직결되는 것은 아니다.
- 성능은 인덱스 스캔 범위, 테이블 엑세스 횟수를 얼마나 줄일 수 있느냐로 결정됨
Index Full Scan
- 수직적 탐색없이 인덱스 리프 블록을 처음부터 끝까지 수평적으로 탐색하는 방식
- 실행계획
create index emp_ename_sal_idx on emp (ename, sal);
set autotrace traceonly exp
select * from emp where sal > 2000 order by ename;
Execution Plan
---------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS
1 0 TABLE ACCESS (BY INDEX ROWID) OF 'EMP' (TABLE)
2 1 INDEX (FULL SCAN) OF 'EMP_ENAME_SAL_IDX' (INDEX)- 데이터 검색을 위한 최적의 인덱스가 없을 때 차선으로 선택됨
- ENAME이 조건절에 없으므로 INDEX RANGE SCAN 불가능
- 그나마 SAL이 인덱스에 있어서 INDEX FULL SCAN 가능
- 효용성
- 인덱스 선두 컬럼(ENAME)이 조건절에 없으면 옵티마이저는 먼저 Table Full Scan 고려
- 대용량 테이블이면 고려 안할 수 있음
- 인덱스 전체 스캔이 테이블 스캔보다 비용이 적다면 인덱스 스캔을 하는 것이 유리하다.
- 이럴 때 옵티마이저는 Index Full Scan 진행
Index Unique Scan
- 수직적 탐색으로만 데이터를 찾는 스캔 방식
- Unique 인덱스를 '=' 조건으로 탐색하는 경우에 작동한다.
- 실행계획
create unique index pk_emp on emp(empno);
alter table emp add
constraint pk_emp primary key(empno) using index pk_emp;
set autotrace traceonly explain
select empno, ename, from emp where empno = 7788;
Execution Plan
-----------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS
1 0 TABLE ACCESS (BY INDEX ROWID) OF 'EMP'
2 1 INDEX (UNIQUE SCAN) OF 'PK_EMP' (UNIQUE)- Unique 인덱스가 존재하는 컬럼은 중복 값이 입력되지 않게 DBMS가 데이터 정합성을 관리
- 범위 검색시에는 Index Range Scan
- Unique 결합 인덱스에 대해 일부 컬럼만으로 검색할 때도 Index Range Scan 동작
- 주문상품 PK 인덱스를 [주문일자 + 고객ID + 상품ID]로 구성했는데, 주문일자와 고객ID로 검색하는 경우를 뜻함
Index Skip Scan
- 인덱스 선두 컬럼을 조건절에 사용하지 않으면 옵티마이저는 기본적으로 Table Full Scan 사용
- 오라클에서 새로 제시한 인덱스 선두 컬럼이 조건절에 없어도 인덱스를 활용하는 새로운 스캔방식
- 조건절에 빠진 인덱스 선두 컬럼의 Distinct Value 개수가 적고 후행 컬럼의 Distinct Value 개수가 많을 때 유용함
- Distinct Value = 카디널리티라고 생각하면 편하다.
Index Fast Full Scan
- Index Full Scan보다 빠름
- 논리적인 인덱스 트리 구조를 무시하고 인덱스 세그먼트 전체를 Multiblock I/O 방식으로 스캔하기 때문
- 대량의 인덱스 블록을 읽어야 할 때 큰 효과를 발휘함
- 속도는 빠르지만, 인덱스 리프 노드가 갖는 연결리스트 구조를 무시한 채 데이터를 읽기 때문에 결과집합이 인덱스 키 순서대로 정렬되지 않는다.
- 쿼리에 사용한 컬럼이 모두 인덱스에 포함돼 있을 때만 사용가능
| Index Full Scan | Index Fast Full Scan |
|---|---|
| 1. 인덱스 구조를 따라 스캔 2. 결과집합 순서 보장 3. SIngle Block I/O 4. (파티션 돼 있지 않다면) 병렬스캔 불가 5. 인덱스에 포함되지 않은 컬럼 조회 시에도 사용 가능 |
1. 세그먼트 전체를 스캔 2. 결과 집합 순서 보장 안됨 3. Multiblock I/O 4. 병렬스캔 가능 5. 인덱스에 포함된 컬럼으로만 조회할 때 사용 가능 |
Index Range Scan Descending
- Index Range Scan과 기본적으로 동일한 스캔 방식
- 인덱스를 뒤에서부터 앞족으로 스캔하기 때문에 내림차순으로 정렬됨
- 거꾸로 읽을 때 유용한 상황에 대해 생각해보자.
'skill > 데이터베이스 튜닝' 카테고리의 다른 글
| 인덱스 튜닝 (0) | 2021.12.28 |
|---|---|
| SQL 처리 과정과 I/O (0) | 2021.11.29 |